
摆脱人工标注魔咒!字节跳动MaskGCT模型用10万小时数据,教会AI自己说话
近期,字节跳动发布了名为MaskGCT的全新语音合成(TTS)模型,该模型在语音质量、相似度和可控性方面取得了显著突破,直接颠覆了传统语音合成(TTS)的玩法,让AI彻底摆脱了对人工标注的依赖,实现了真正意义上的“自学成才”。
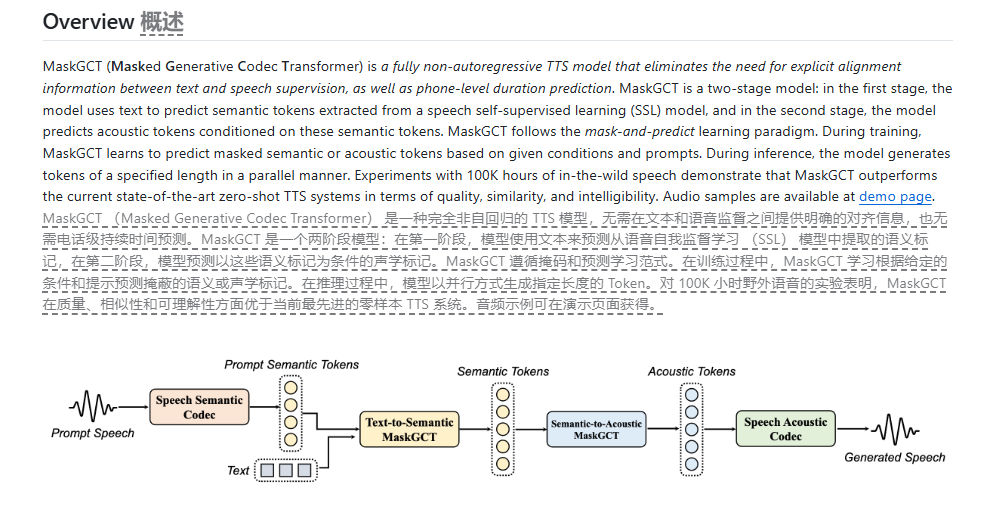
传统的TTS系统,就像一个被溺爱的孩子,必须得人工一字一句地教它说话,先把文本和语音对齐,再预测每个音节的时长,最后才能磕磕绊绊地合成语音。这种方式,不仅效率低,而且生成的语音也缺乏自然流畅的韵律。
而字节跳动这次祭出的MaskGCT,则完全抛弃了这种老旧的模式。它采用了掩码生成式编解码器Transformer的架构,简单来说,就是用一个类似BERT的模型,先把语音转换成语义特征,再根据这些语义特征,用另一个模型预测声学特征,最后合成语音。
这套玩法,最大的亮点就在于它完全不需要人工标注。它直接用10万小时的未标注语音数据进行训练,让模型自己从海量数据中学习文本和语音之间的对应关系。
这就好比,把一个孩子扔到语言环境里,让他自己去摸索学习,最终自然而然地掌握语言。
MaskGCT的另一个牛逼之处在于,它可以像人一样灵活地控制语音的时长,想快就快,想慢就慢。这对于需要进行配音或语音编辑的场景来说,简直是福音。
实验结果也证明了MaskGCT的实力。在语音质量、相似度、韵律和清晰度方面,它都吊打了现有的各种TTS系统,甚至达到了可以跟真人媲美的水平。
更可怕的是,MaskGCT不仅能生成高质量的语音,还能模仿不同说话者的风格,甚至可以跨语言进行语音翻译,简直就是一个六边形战士。
当然,MaskGCT目前还有一些局限性,比如在处理大幅度面部姿势的语音合成时,可能会出现一些瑕疵。但瑕不掩瑜,MaskGCT的出现,无疑为TTS领域开辟了新的天地,也为我们未来的人机交互体验带来了无限的想象空间。
在线体验:https://huggingface.co/spaces/amphion/maskgct
项目地址:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
备注:资讯来源AIbase基地编辑:一起学习网
标签:语音,模型,语义,特征,韵律,语言,先把,玩法,语音合成,字节